
Global Cocoa Price Forecasting with Hybrid ML Framework
Overview
Forecasting commodity prices requires models that can handle both long-term trends and sudden volatility shifts. This senior capstone project tackled global cocoa price prediction using over 6,000 daily observations spanning 1994 to 2024, developing a hybrid framework that prioritizes interpretability and statistical rigor over raw algorithmic complexity.
Motivation
My interest in this problem grew from a broader curiosity about how uncertainty impacts temporal dynamics. Commodity markets are a natural testbed: prices are driven by overlapping factors — weather, geopolitics, supply chain shocks — and any single modeling paradigm tends to fail under regime changes. The goal was not just to forecast prices, but to build a pipeline where each modeling decision was justified by residual diagnostics rather than arbitrary complexity.
Approach
Phase 1 — ARIMA Baseline
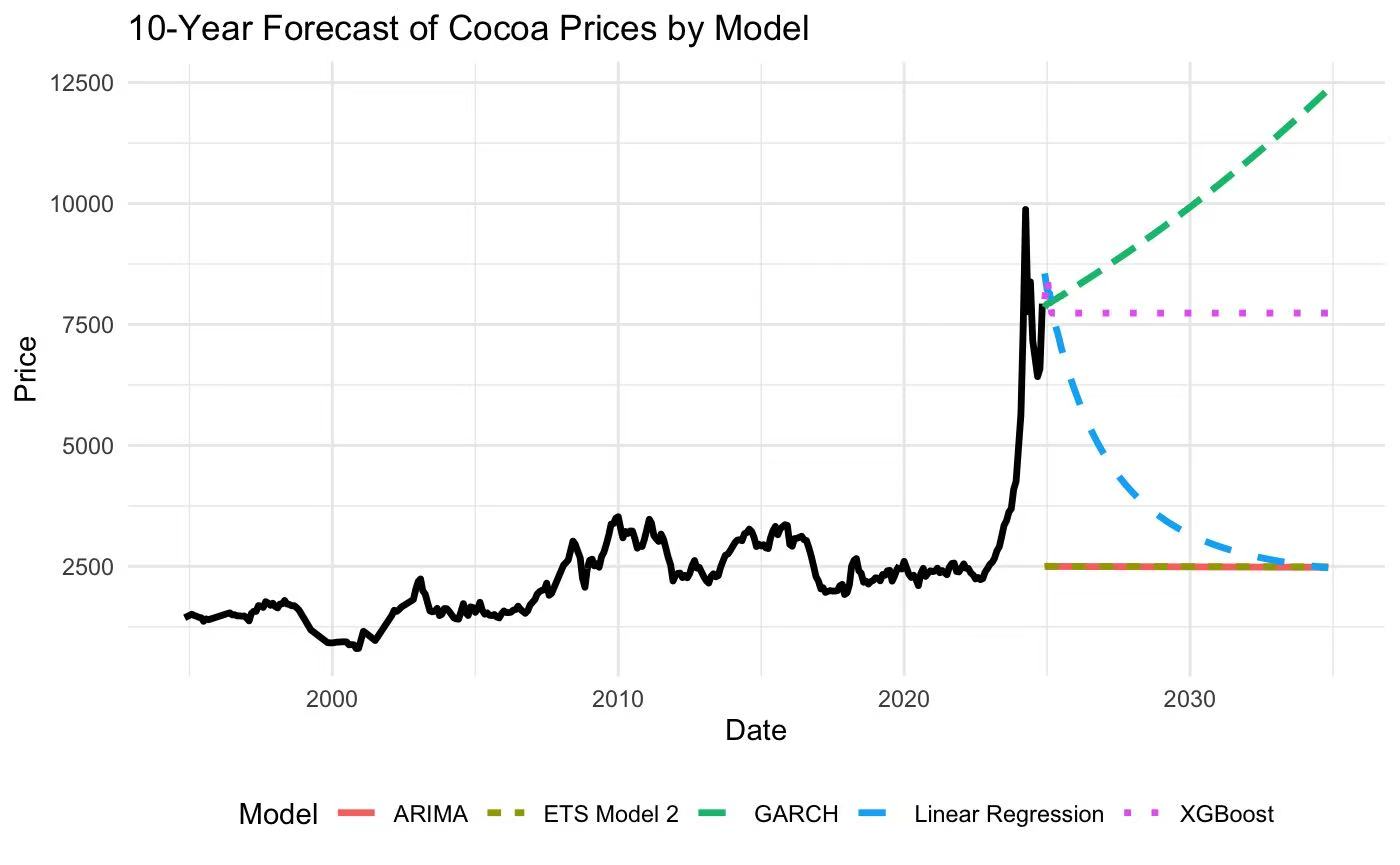
Initial ARIMA-based models captured long-term trends effectively. However, during periods of high volatility — such as supply disruptions or speculative surges — the model consistently overpredicted, revealing a fundamental limitation of linear autoregressive assumptions.
Phase 2 — XGBoost
To address this, I transitioned to XGBoost for improved flexibility in capturing nonlinear relationships. While predictive accuracy improved, residual diagnostics showed that the model was still ignoring critical temporal dependencies — the structured autocorrelation in the residuals indicated that simply adding algorithmic complexity wasn’t enough.
Phase 3 — Hybrid Framework
Moving beyond raw algorithmic complexity, I designed a hybrid framework that integrated time-series structure (to respect the temporal ordering and autocorrelation) with external drivers (macroeconomic indicators, supply-side signals). The design prioritized interpretability: each component’s contribution could be isolated and validated, making the model’s behavior transparent to domain experts.
Diagnostics-Driven Iteration
Every model transition was motivated by careful residual analysis — checking for autocorrelation, heteroscedasticity, and distributional assumptions — rather than simply stacking more complex architectures. This approach ensured that improvements were statistically grounded.
Results
- Achieved a final MAPE of 5.39%, significantly improving over both ARIMA and standalone XGBoost baselines
- Successfully captured volatility regimes that pure autoregressive models missed
- Demonstrated that model utility lies in interpretability and diagnostic-driven design, not just predictive accuracy
Key Takeaway
This project reinforced a core principle from my studies in nonlinear optimization and statistical inference: true model utility lies not in raw predictive performance, but in designing architectures that ensure reliability and interpretability. The diagnostics-driven workflow became a template for how I approach all subsequent modeling problems.